This sample demonstrates the instancing feature available with Direct3D 9. A vs_3_0 device is required for the hardware version of this feature. The sample also shows alternate ways of achieving results similar to hardware instancing, but for adapters that do not support vs_3_0. The shader instancing technique shows the benefits of efficient batching of primitives.

How the Sample Works
The sample demonstrates four different rendering techniques to achieve the same result: to render many nearly identical boxes (objects with small numbers of polygons) in the scene. The boxes differ by their position and color.
The user can vary the number of boxes in the scene between one and 1000. Use the sample to monitor performance as the number of boxes increases. As you change the number of boxes, the vertex and index buffer resources are recreated by OnCreateBuffers and OnDestroyBuffers.
Technique 1: Hardware Instancing
Hardware instancing requires a vs_3_0-capable device. The instance-specific data is stored in a second vertex buffer. The rendering is implemented in the sample application's OnRenderHWInstancing method. IDirect3DDevice9::SetStreamSourceFreq is used with D3DSTREAMSOURCE_INDEXEDDATA to specify the number of boxes and with D3DSTREAMSOURCE_INSTANCEDATA to specify the frequency of the instance data (in this case, frequency equals one).
Drawing the scene is accomplished as follows:

Technique 2: Shader Instancing (with Draw Call Batching)
This is the most efficient technique that does not use the hardware to perform the instancing. One call to IDirect3DDevice9::DrawIndexedPrimitive handles multiple primitives at once. The instance data is stored in a system memory array, which is then copied into the vertex shader's constants at draw time. Since vs_2_0 only guarantees 256 constants, it is not possible for the entire array of instance data to fit at once. This sample's .fx file can only batch-process 120 constants (one float4 is required for box position, and one float4 is required for box color). Rendering is performed in the sample's OnRenderShaderInstancing method.

This method would also work on a vs_1_1 part, although not as efficiently because vs_1_1 only guarantees 96 constants. This means that batching is nearly three times more efficient on vs_2_0 hardware than on vs_1_1 hardware, but even on vs_1_1 hardware, batching still outperforms no batching.
Technique 3: Constants Instancing (without Draw Call Batching)
This technique is somewhat similar to Technique 2 without the batching (batch size = 1). It will render one box at a time, by first setting its position and color and then calling DrawIndexedPrimitive. The technique is implemented in the sample's OnRenderConstantsInstancing method.
Technique 4: Stream Instancing
As in Technique 1, this technique uses a second vertex buffer to store instance data. Instead of setting vertex shader constants to update the position and color for each box, this technique changes the offset in the instance stream buffer and draws one box at a time. The technique is implemented in the sample's OnRenderStreamInstancing method.
CPU- vs. GPU-bound
When the sample renders a large number of boxes, only Techniques 1 and 2 are GPU-bound, while Techniques 3 and 4 waste many CPU cycles by making numerous calls per frame to DrawIndexedPrimitive.
The performance numbers for rendering a large number of boxes show that only the first two techniques are GPU-bound, while the last two techniques waste a lot of CPU cycles by making numerous calls to DrawIndexedPrimitive per frame. To better illustrate the penalty from being CPU-bound in a real world application, the sample has the Goal option which simulates a secondary task (in a game, this could be AI or physics) competing for CPU. The sample queries the time elapsed since the last frame and if there is time remaining inside the goal time/frame, the sample allows time to pass to represent game logic. It reports the amount of time used in the Remaining for logic statistic. This is the percentage of CPU cycles that are available to spend on non-rendering algorithms such as game logic or physics; the higher the percentage, the better. If the scene is loaded with 1000 boxes, it was observed that the efficient techniques have 2x better CPU efficiency than the CPU-bound techniques. In other words, using Techniques 3 and 4 to render many instances will starve other tasks of CPU time.
The following table summarizes hardware and memory requirements for different rendering techniques:

하드웨어 인스턴싱
하드웨어 인스턴싱은 정점 셰이더 3.0을 지원하는 그래픽카드가 필요하다. 하드웨어 인스턴싱은 특정한 인스턴싱 데이터가 세컨드 정점버퍼에 들어가게 된다. 샘플의 OnRenderHWInstancing 함수를 통해 구현된다.
여기서 IDirect3DDevice9::SetStreamSourceFreq 함수가 상자 수를 지정하기 위한 매크로 상수 D3DSTREAMSOURCE_INDEXEDDATA, 인스턴스 데이터의 주기를 지정하기 위한 매크로 상수 D3DSTREAMSOURCE_INSTANCEDATA가 함께 사용된다. (이 경우에 , 빈도는 1이다.)
드로우 함수

로 장면이 출력된다.
셰이더 인스턴싱 (Draw Call Batching 사용)
하드웨어를 사용하지 않는 가장 효율적인 인스턴싱 기법이다. IDirect3DDevice9::DrawIndexedPrimitive 함수는 여러 프리미티브(점, 선, 폴리곤, 렌더링 최소단위)를 한번에 (인덱스 버퍼 내에 지정한 만큼) 처리한다. 인스턴스 데이터는 시스템 메모리에 저장되어 드로우 타임에 버텍스 셰이더에 상수에 복사된다.
(시스템 메모리는 RAM 일 수 있고 V-RAM 일 수 있다)
버텍스 셰이더 2.0은 256개의 상수만 보장하기 때문에 전체 인스턴스 데이터의 감당이 불가능하다.
예제 샘플의 fx파일은 120개의 상수만 처리가 가능하다. 상자 위치뿐만 아니라 색상까지 포함해 두개의 float4가 필요하기 때문에 절반의 용량이 날라간다
OnRenderShaderInstancing 메서드에서 수행된다
이러한 방식은 버텍스 셰이더 1.1버전에서도 작동하지만 최대 96개의 상수만 담을 수 있고, 이 때문에 효율적이진 않다. 그러나 이 기법을 사용해야 할 때 쓰지 않는 것보단 쓰는게 효율이다.
상수 인스턴싱 (Draw Call Batching 사용 안함)
해당 방식은 Batching을 사용하지 않은 셰이더 인스턴싱과 비슷하다(배치 사이즈가 1이다).
이러한 방식은 위치, 색상을 먼저 설정하고 DrawIndexedPrimitive 함수를 통해 박스를 한 번에 하나씩 렌더링한다.
OnRenerConstantsInstancing 함수에서 볼 수 있다.
스트림 인스턴싱
하드웨어 인스턴싱은 인스턴스 데이터를 세컨드 버텍스 버퍼에 담는 방식으로 구현되었다. 정점 셰이더 상수로 데이터의 위치, 색상값을 각각의 박스(모델)마다 갱신하던 반면에, 스트림 인스턴싱은 인스턴스 스트림 버퍼의 오프셋을 변경하고 한번에 하나씩 박스를 그린다.
CPU- 대 GPU 바인딩
샘플이 많은 수의 박스를 렌더링할 때 매개 변수 1과 2만 GPU로 바인딩된 반면 매개 변수 3과 4는 프레임당 수많은 DrawIndexedPrimitive 함수 호출로 하여 많은 CPU 사이클을 낭비한다.
많은 수의 박스를 렌더링하는 동안, 퍼포먼스 결과는 처음 두 기법만이 GPU-bound인 반면, 마지막 두 기법은 프레임당 수많은 DrawIndexedPrimitive 호출을 함으로써 많은 CPU 사이클을 낭비한다는 것을 보여준다.
실제 애플리케이션에서 CPU 바인딩으로 인한 손실을 더 잘 설명하기 위해 샘플에는 CPU자원을 더 긁어대기 위한 보조 작업(게임에서 AI 또는 물리)을 시뮬레이션하는 추가적인 옵션이 존재한다.
[ 샘플은 마지막 프레임 이후 경과된 시간을 쿼리하고, 골 시간/프레임 내에 남은 시간이 있을 경우 샘플은 게임 논리를 나타낼 수 있는 시간을 허용한다.
그것은 논리 통계에 대해 남은 시간 통계에 사용된 시간을 보고한다.
이는 게임 논리나 물리학과 같은 비렌더링 알고리즘에 사용할 수 있는 CPU 사이클의 비율이며, 비율이 높을수록 좋다.
씬(scene)이 1000박스로 로드되면 효율적인 기법이 CPU 바인딩 기법보다 2배 높은 CPU 효율을 갖는다는 것이 관찰됐다.
즉, 매개 변수 3과 4를 사용하여 많은 인스턴스를 렌더링하면 CPU 시간의 다른 작업이 중단된다.
다음 표에는 다양한 렌더링 기법에 대한 하드웨어 및 메모리 요구 사항이 요약되어 있다. ] - 파파고
모든 장면 렌더는

해당 케이스문 안의 함수에 존재한다.
하드웨어 인스턴싱


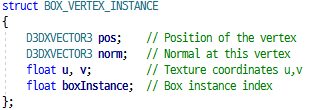
정점 선언, 정점 셰이더의 인풋 구조체 값이다. 정점의 위치, 법선, 텍스처 좌표, 색상 1, 색상 2
(색상1, 2는 인스턴스 데이터를 색상 시맨틱으로 넣어준 것 뿐이다.)

메인 버텍스 버퍼를 만든다. 메인 버텍스 버퍼에는 인스턴싱 할 오브젝트의 정점이 들어간다

인덱스 버퍼, 여기까진 일반적인 버퍼 생성과 다를게 없다.



메인 버텍스 버퍼에 값을 채웠다


세컨드 버텍스 버퍼, 세컨드 버텍스 버퍼에는 인스턴스 데이터가 들어간다.(위치 등)


세컨드 버텍스 버퍼에 색상과 위치, 회전값을 넣어줬다.
장면 렌더


여기서 스트림소스프리퀀시 함수는, 메인 버텍스 버퍼의 정점들을 몇번 반복할건지 설정하는 역할을 한다.

세컨드 버텍스 버퍼의 스트림을 장치에 연결하고, 프리퀀시 함수로 인스턴싱 데이터가 들어있는 스트림을 식별한다. 각 버텍스마다 하나의 인스턴스 데이터를 가지고 있기 때문에 1과 or 논리연산을 한다고 하는데, 이건 무슨 소린지 잘 모르겠다.
정점 선언된 부분을 보면 스트림소스 0번과 1번을 나눠놓았던 것을 볼 수 있다. 메인 버텍스 버퍼의 정보는 버텍스 좌표와 노말과 uv밖에 없다. 세컨드 버텍스 버퍼에는 색상과 (BYTE로 쪼갠) xyz 좌표, rotate 값이 들어있다.
이 두 버퍼의 포인터와 데이터 스트림(구조체 정보)을 장치에 바인드해주는 것이다.




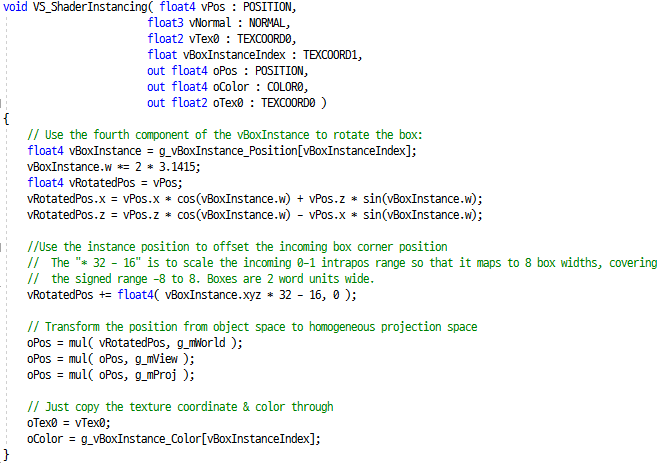
셰이더에서는 회전값을 주는것과 x, z 방향으로 살짝씩 거리를 벌려서 배치해주고, 나머지는 일반적인 셰이더에서 해주는 일과 동일하다.
vColor와 vBoxInstance가 인스턴스 데이터인데, 정점 선언 된 부분에서 스트림 번호를 1로 해준 것을 참고
셰이더 인스턴싱
언제 다하냐


마지막 인자는 인스턴스 데이터다

셰이더 인스턴싱은 버텍스 버퍼를 하나만 사용한다.
보면 버텍스 버퍼에 인스턴싱할 갯수를 곱한 것이 보인다 (g_nNumBatchInstance)
또한, 정점 정보에 boxInstance라는 인스턴스 데이터가 들어가있다.
버텍스 버퍼를 두개로 나눠 쓰던 하드웨어 인스턴싱과는 꽤 다른 모습이다.

g_nNumBatchInstance를 사용한 인덱스 버퍼






장면 렌더

SetStreamSource에 들어갈 stride 사이즈에 주의, 여기서 BOX_VERTEX_INSTANCE의 크기만큼 offset을 벌려주는데, 즉 기존의 정점 정보를 그대로 사용하면 안된다는 것이다.
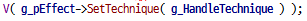




여기서 한번에 최대 120개까지만 렌더를 하는데, 구현하기에 따라 다를 듯 하다. 아무튼 이런 방식으로 벡터 배열을 넘겨주고, 전역변수로 선언된 위치, 색상 정보의 배열을 넘겨주기도 한다.
g_vBoxInstance_Position과 _Color는 셰이더로 넘어간다.



SetVectorArray 함수를 타고 해당 배열로 넘어왔다.
정점 정보에 인스턴스 인덱스를 끼워넣어 보내준다. 간-단
상수 인스턴싱


상수 인스턴싱을 위한 정점 선언, 깔끔하게 모델만을 위한 정점 정보밖에 없다.
버텍스 버퍼를 채우는 것은 하드웨어 인스턴싱의 방법과 같다
인스턴스 데이터를 채워넣는 것은 셰이더 인스턴싱의 방법과 같다. 마찬가지로 전역으로 선언된 배열에 정보를 집어넣는다.
장면 렌더

아 이거 한번에 하나씩 그리는거네ㅋㅋㅋ

셰이더 인스턴싱과 달리 배열이 아닌 단일 변수다. 한번에 하나씩이라는 의미.

CPU에서 계속 DP를 날려주는 방식이다. 이런 방식도 인스턴싱이라고 한 이유가 있었구나
스트림 인스턴싱


하드웨어 인스턴싱과 같다










장면 렌더






인스턴스 데이터를 넣은 세컨드 버텍스 버퍼를 한 번 그릴때 하나씩 장치에 바인드한다.
하드웨어 인스턴싱과 비교하면서 보면 된다.
SetStreamSource 세번째 인자의 의미는 그리기 시작할 정점의 위치를 나타낸다. 네번째 인자는 정점이 차지하는 바이트 수인데, 0으로 설정하면 어떻게 돌아가는건지 잘 모르겠다...
다만 확실한 것은 nRemainingBoxes가 늘어나면서 SetStreamSource 함수를 호출할 때 읽어야 할 시작점 하나는 명확히 짚고 넘어간다는 것이다.

스트림 인스턴싱의 정점셰이더는 하드웨어 인스턴싱의 그것과 동일하다.
이해는 되는데, 깨끗하게 머리에 들어오지가 않는다. 짜증난다;
참고
유니티 게임 엔진에서의 드로우콜이란? / Draw Call in Unity Game Engine? – Rapapa Dev Story
개발자인 아는 지인이 면접을 보았는데, “Draw Call에 대해서 아느냐?” 라는 식의 질문을 받았었다. 모바일 게임 업계에서도 De Facto Standard로서 Unity가 자리 잡혀가고 있는 시점에서 이 Draw Call이
rapapa.net
Dynamic Batching이 효율적일까?
배칭이란 무었인가? 드로우 콜(DC)을 줄이기 위한 방법중 하나로 크게 정적배칭과 동적배칭으로 나뉜다. 그렇다면 DC란 무었이고 왜 줄여야 하는가? DC란 그냥 CPU가 GPU에게 메시를 그려달라는 명��
mgun.tistory.com
m.blog.naver.com/sorkelf/40160183951
인스턴싱 (Instancing)
인스턴싱 (Instancing) : 동일한 객체(오브젝트)를 한 화면에 여러개를 렌더링 시킬 경우에 한번의 DP ...
blog.naver.com
www.gpgstudy.com/forum/viewtopic.php?p=96686
한캐릭터를 많이 그리는 법 없나요? - GpgStudy 포럼
2D, 3D, 다각형, 픽셀 등 게임의 그래픽 프로그래밍에 관한 포럼입니다. 운영자: 류광 korean86 전체글: 48 가입일: 2005-01-18 07:43 전체글 글쓴이: korean86 » 2008-03-14 09:13 온라인게임을 보면 수많은 케릭��
www.gpgstudy.com
유니티 그래픽스 최적화 - 4. 드로우콜과 배칭 (Draw Call & Batching)
. . 4. 드로우콜과 배칭 (Draw Call & Batching) 4-1 드로우콜 (Draw Call) 수많은 병목지점이 있지만, 드로우콜이 병목인 경우가 많다. 최적화를 많이 간과하기 때문. 01) 드로우콜의 이해 CPU가 GPU에 오브젝��
wonsorang.tistory.com
docs.microsoft.com/en-us/windows/win32/direct3d9/efficiently-drawing-multiple-instances-of-geometry
Efficiently Drawing Multiple Instances of Geometry (Direct3D 9) - Win32 apps
Efficiently Drawing Multiple Instances of Geometry (Direct3D 9) In this article --> Given a scene that contains many objects that use the same geometry, you can draw many instances of that geometry at different orientations, sizes, colors, and so on with d
docs.microsoft.com
드로우 콜과 텍스처 아틀라스와 배치와 인스턴싱
1. 드로우 콜 draw call: CPU가 OpenGL이나 DirectX의 함수를 호출하여 GPU에게 그리기(draw call)을 요청하는 것. 그래픽 API의 모든 드로우콜은 CPU상의 상당한 퍼포먼스 오버헤드를 일으킨다. draw call을 줄이
strange-cpp.tistory.com
www.slideshare.net/noerror/06-8209872
06_게임엔진 활용팁
게임 엔진(2) 활용팁 김성익(noerror@hitel.net) 2006.4.30
www.slideshare.net
유니티 최적화 : 배칭과 드로우콜
※ 본 글은 개인적인 기록용으로 작성됨. 본문 중 잘못된부분이 있다면 알려주시면 감사하겠습니다. [ 참고자료 ] 오즈라엘님 Unity 2016 강연 : http://www.slideshare.net/ozlael/unite-seoul-2016-60714130 유..
mentum.tistory.com
Dynamic Batching이 효율적일까?
배칭이란 무었인가? 드로우 콜(DC)을 줄이기 위한 방법중 하나로 크게 정적배칭과 동적배칭으로 나뉜다. 그렇다면 DC란 무었이고 왜 줄여야 하는가? DC란 그냥 CPU가 GPU에게 메시를 그려달라는 명��
mgun.tistory.com